我开始用 AI 给自己“提前配音”了
以前我剪视频,总觉得左右手在互相打架——脚本明明写好了,声音却没跟上,画面就像断了线的风筝,怎么拽都拽不回来。要是先把配音录了吧,素材又堆成了山,画面还没拼完,脚本可能已经改了好几版,结果同一句话得反反复复录,录到自己都烦了。录完皱着眉头听回放,总觉得这里语气不对,那里停顿别扭,节奏老是踩不到点上。
特别是做叙事类视频的时候,声音早就不只是声音了,甚至有的时候是根据声音找素材。

所以有没有什么方式,可以提前预设一下配音呢?现在AI这么强大了,能否先让 AI 帮我生成了一个“临时旁白”,这样粗剪视频的时候,就能让整个视频的节奏具体一些。
没错,就是TTS,最近刚好尝试了Qwen3-TTS的声音克隆,效果还是很不错的。
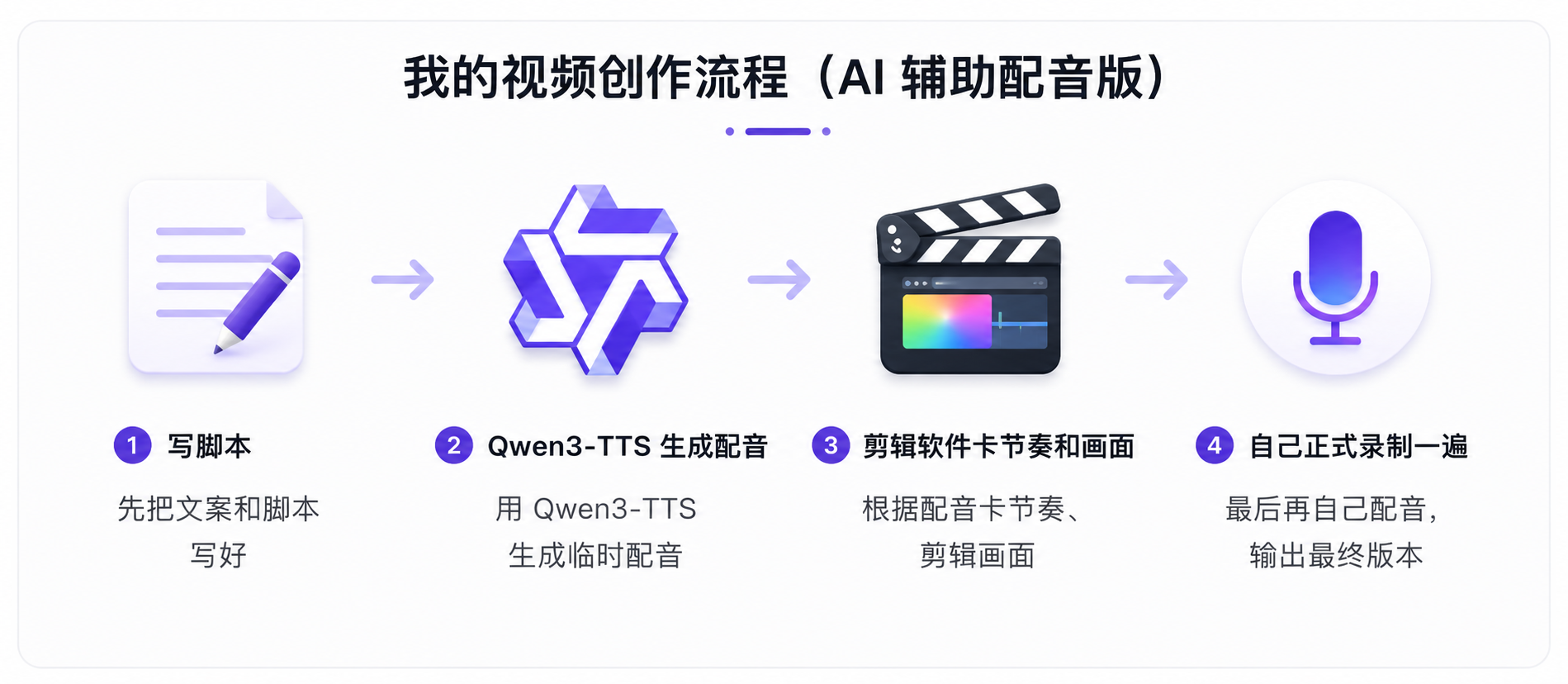
于是现在的新 workflow 慢慢变成了:
先写脚本,然后用 Qwen3-TTS 直接生成配音,再把音频丢进剪辑软件里,根据声音去卡节奏和画面,最后再自己正式录制一遍。
现在的TTS早就不只是念稿子了。它带着情绪,懂得停顿,甚至能在你剪辑时,把那些原本只存在于脑中的情绪、节奏和镜头切换,一帧帧“长”出来。
有时AI配音里一个意外的停顿,反而会猛地撞开你剪辑的新视角。
以前总担心AI会让创作变得机械。可真正用起来才发现,它更像一个“预演工具”——不会取代你,而是先替你跑通整条情绪的脉络。
等到你真正录人声的时候,反而更容易进入状态,因为脑海里已有一张清晰的情绪地图。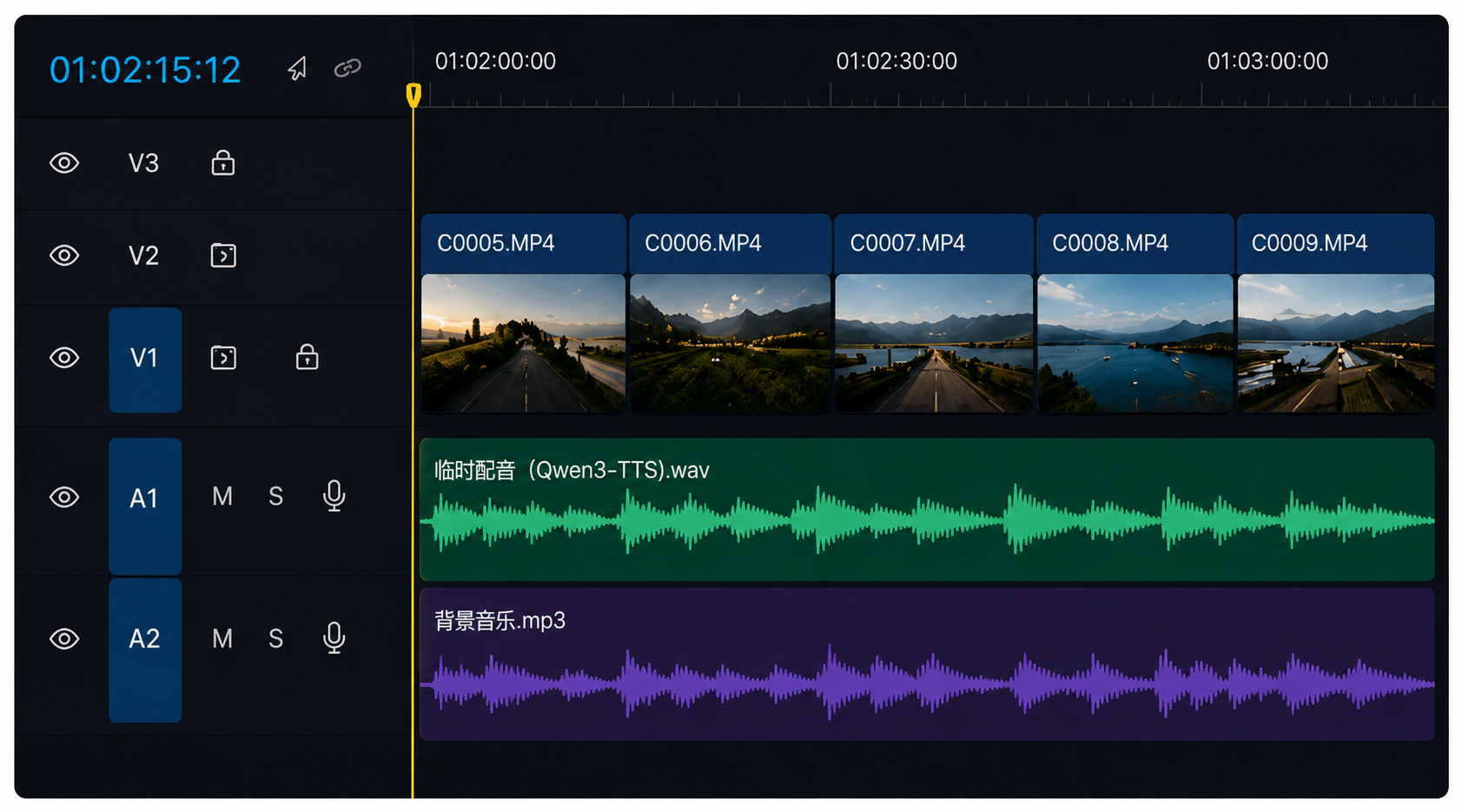
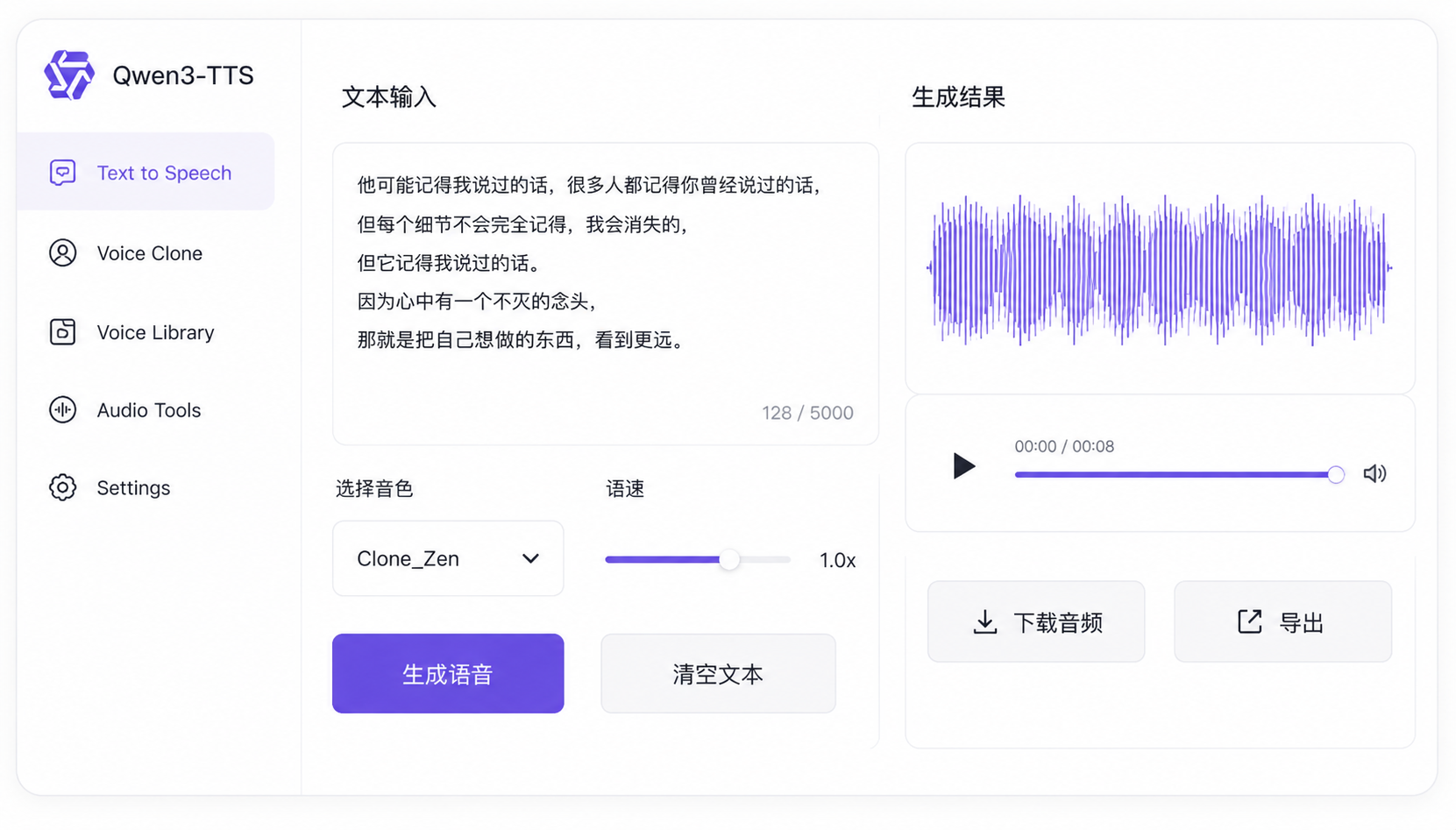
最让我震惊的是,它真的复刻了我的声音。我本以为声音克隆需要海量数据,没想到2026年的今天,几秒钟的音频就能捕捉到90%的相似度。
实际测试时,那些语气、停顿,甚至我自己都没太注意的说话习惯,它都学得很像。
当然,仔细听还是能分辨出来。但用在视频粗剪阶段,已经绰绰有余了。
有时播着播着,我会突然恍惚——这到底是AI,还是我自己在说话?
这种感觉,确实有点魔幻。
不过相比于“像不像”,真正让我安心的,反而是另一件事:它可以完全本地运行。
因为现在很多在线声音克隆工具,本质上都需要上传声音数据。但声音这种东西,其实比照片更私人。你的语气、停顿、说话习惯,本身就已经是“另一个你”了。
所以 Qwen3-TTS 让我觉得最惊艳的点,就是它不需要把这些东西交给云端,并且只需要一个1.7B的模型就能复刻,这就意味着基本上消费级电脑都可以很流畅的运行。
至少现在的我,已经开始慢慢离不开这种 workflow 了,这一次我去新西兰的旅拍vlog粗剪时,就是用的这套能力。它不是在替代创作。更像是在帮创作者,把脑子里的东西,更顺畅地表达出来。

为了搭配这个小模型的使用,我还vibecoding了一个macos客户端,有兴趣的小伙伴也可以关注一下,给个star哦~👉 https://github.com/YueYongDev/voicecraft